كيفية استخراج النص من ملفات PDF باستخدام Google Apps Script

يقوم نظام محاسبة خارجي بإنشاء إيصالات ورقية لعملائه والتي يتم بعد ذلك مسحها ضوئيًا كملفات PDF وتحميلها إلى مجلد في Google Drive. يجب تحليل هذه الفواتير بتنسيق PDF ويجب استخراج معلومات محددة، مثل رقم الفاتورة وتاريخ الفاتورة وعنوان البريد الإلكتروني للمشتري وحفظها في جدول بيانات Google.
إليك نموذج فاتورة بتنسيق PDF سنستخدمه في هذا المثال.
سيقرأ البرنامج النصي لمستخرج PDF الملف من Google Drive ويستخدم Google Drive API للتحويل إلى ملف نصي. يمكننا بعد ذلك استخدام RegEx لتحليل هذا الملف النصي وكتابة المعلومات المستخرجة في ورقة Google.
دعونا نبدأ.
الخطوة 1. تحويل PDF إلى نص
على افتراض أن ملفات PDF موجودة بالفعل في Google Drive، فسنكتب وظيفة صغيرة لتحويل ملف PDF إلى نص. يرجى التأكد من Advanced Drive API كما هو موضح في هذا البرنامج التعليمي.
/*
* Convert PDF file to text
* @param {string} fileId - The Google Drive ID of the PDF
* @param {string} language - The language of the PDF text to use for OCR
* return {string} - The extracted text of the PDF file
*/
const convertPDFToText = (fileId, language) => {
fileId = fileId || '18FaqtRcgCozTi0IyQFQbIvdgqaO_UpjW'; // Sample PDF file
language = language || 'en'; // English
// Read the PDF file in Google Drive
const pdfDocument = DriveApp.getFileById(fileId);
// Use OCR to convert PDF to a temporary Google Document
// Restrict the response to include file Id and Title fields only
const { id, title } = Drive.Files.insert(
{
title: pdfDocument.getName().replace(/\.pdf$/, ''),
mimeType: pdfDocument.getMimeType() || 'application/pdf'
},
pdfDocument.getBlob(),
{
ocr: true,
ocrLanguage: language,
fields: 'id,title'
}
);
// Use the Document API to extract text from the Google Document
const textContent = DocumentApp.openById(id).getBody().getText();
// Delete the temporary Google Document since it is no longer needed
DriveApp.getFileById(id).setTrashed(true);
// (optional) Save the text content to another text file in Google Drive
const textFile = DriveApp.createFile(`${title}.txt`, textContent, 'text/plain');
return textContent;
};الآن بعد أن أصبح لدينا المحتوى النصي لملف PDF، يمكننا استخدام RegEx لاستخراج المعلومات التي نحتاجها. لقد قمت بتسليط الضوء على عناصر النص التي نحتاج إلى حفظها في ورقة Google ونمط RegEx الذي سيساعدنا في استخراج المعلومات المطلوبة.
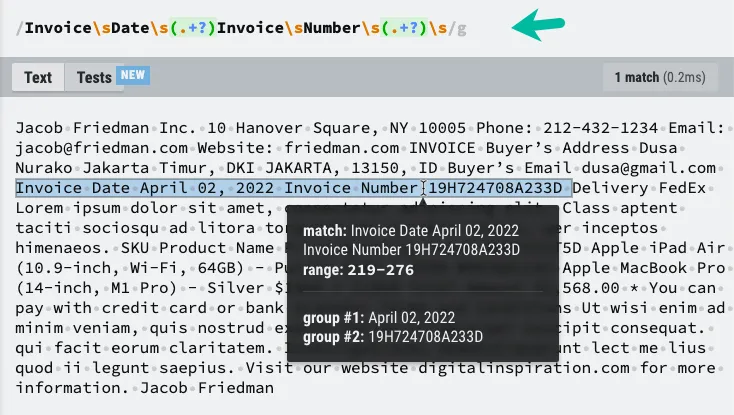
const extractInformationFromPDFText = (textContent) => {
const pattern = /Invoice\sDate\s(.+?)\sInvoice\sNumber\s(.+?)\s/;
const matches = textContent.replace(/\n/g, ' ').match(pattern) || [];
const [, invoiceDate, invoiceNumber] = matches;
return { invoiceDate, invoiceNumber };
};قد تضطر إلى تعديل نمط RegEx بناءً على البنية الفريدة لملف PDF الخاص بك.
الخطوة 3: حفظ المعلومات في ورقة جوجل
هذا هو الجزء الأسهل. يمكننا استخدام Google Sheets API لكتابة المعلومات المستخرجة بسهولة في ورقة Google.
const writeToGoogleSheet = ({ invoiceDate, invoiceNumber }) => {
const spreadsheetId = '<<Google Spreadsheet ID>>';
const sheetName = '<<Sheet Name>>';
const sheet = SpreadsheetApp.openById(spreadsheetId).getSheetByName(sheetName);
if (sheet.getLastRow() === 0) {
sheet.appendRow(['Invoice Date', 'Invoice Number']);
}
sheet.appendRow([invoiceDate, invoiceNumber]);
SpreadsheetApp.flush();
};إذا كنت تستخدم ملف PDF أكثر تعقيدًا، فقد تفكر في استخدام واجهة برمجة التطبيقات التجارية التي تستخدم التعلم الآلي لتحليل تخطيط المستندات واستخراج معلومات محددة على نطاق واسع. تشمل بعض خدمات الويب الشائعة لاستخراج بيانات PDF Amazon Textract وAdobe’s Extract API وVision AI الخاص بشركة Google. .تقدم جميعها مستويات مجانية سخية للاستخدام على نطاق صغير.

اكتشاف المزيد من مربى سبورت - أخبار وتحليلات كرة القدم
اشترك للحصول على أحدث التدوينات المرسلة إلى بريدك الإلكتروني.




